Publications
Recent Publications (Refer to this Google Scholar Page for the Full List of Publications)
Authors with underlined bold text represent the first authors of the publication.
The superscript asterisk (*) indicates the corresponding author.
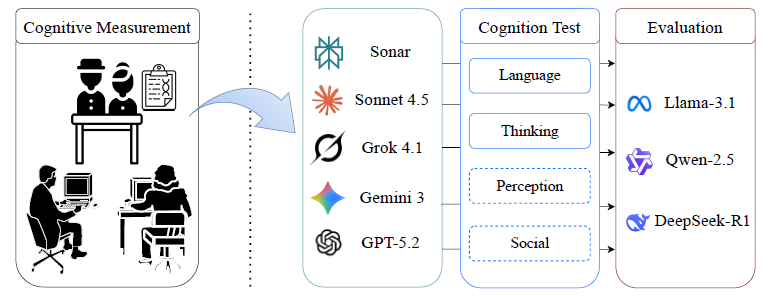
A Clinically Inspired Framework for Cognitive Evaluation of Large Language Models
Information Sciences 2026 (accepted) [JCR JCI Top 10% in Computer Science, Information Systems]
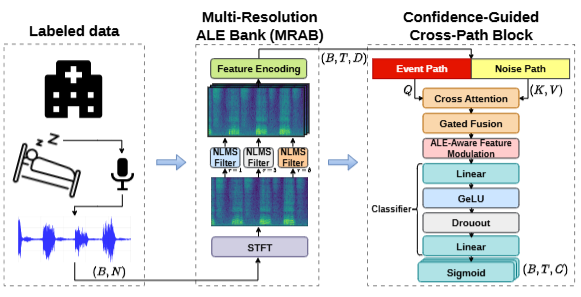
Sleep Sound Event Detection Powered by Learnable Multi-Resolution Adaptive Line Enhancer
Proc. Interspeech, 2026. (The Long Paper Track) - acceptance rate under 30 %
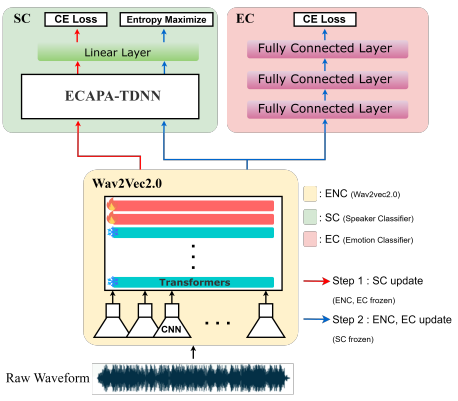
SISER : Speaker Invariant for Speech Emotion Recognition
Proc. Interspeech, 2026.
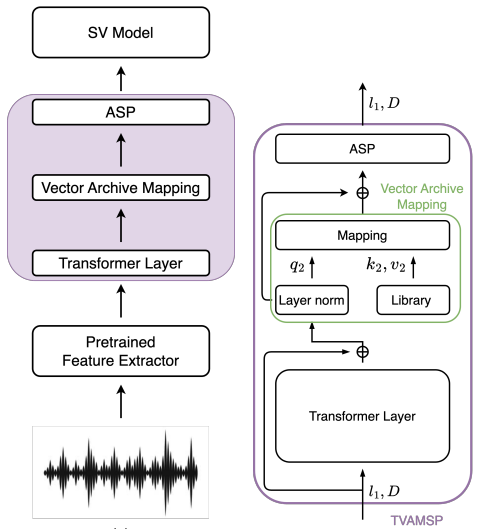
Beyond Short Segments : Expanding Speaker Embeddings with Vector Archives
Proc. Interspeech, 2026.
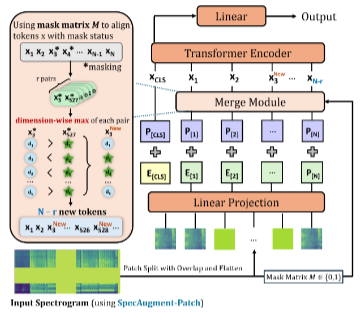
From Masking to Merging: Rethinking SpecAugment for Efficient Audio Spectrogram Transformer
Proc. Interspeech, 2026.

Efficient Punctuation Restoration via Weighted Lookahead Scoring Method for Streaming ASR Systems
Proc. IJCNN, 2026.
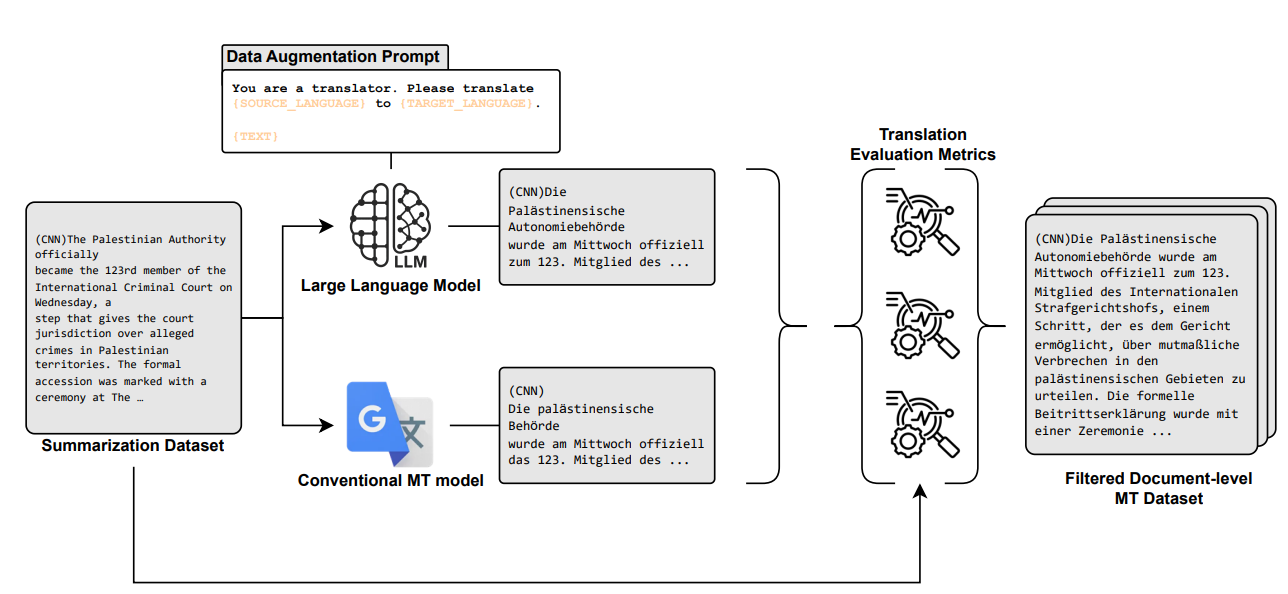
Enhancing Document-Level Machine Translation via filtered synthetic corpora and two-stage LLM adaptation
Proc. ICASSP, 2026.
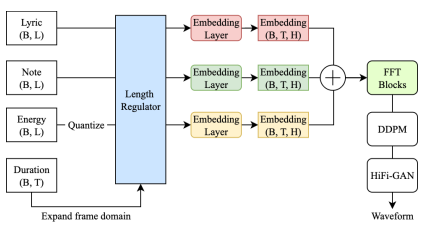
Controllable Singing Voice Synthesis using Phoneme-Level Energy Sequence
Proc. ASRU, 2025.
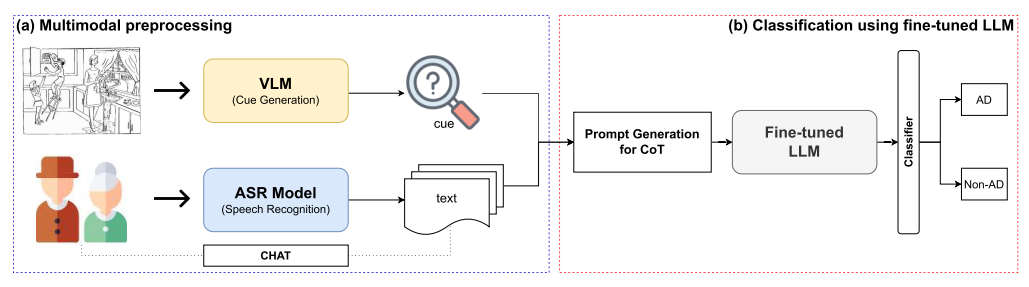
A Novel Chain-of-Thought Reasoning Approach for Alzheimer’s Disease Detection Using Large Language and Vision-Language Models
IEEE Trans. Neural Systems and Rehabilitation Engineering Nov. 2025 (TNSRE) (Top 2% in the JCR category of "Rehabilitation")
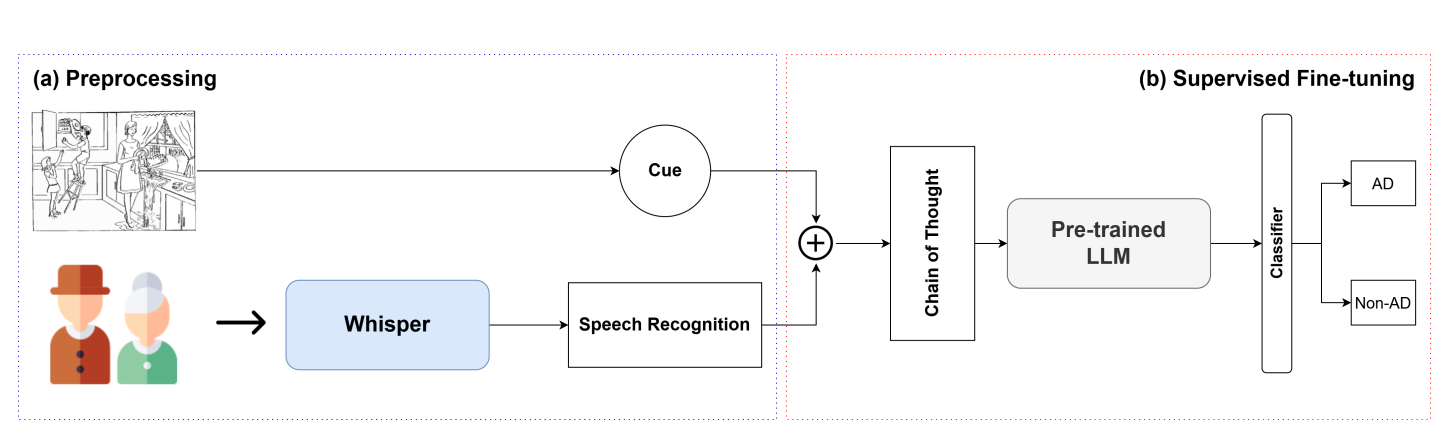
Reasoning-Based Approach with Chain-of-Thought for Alzheimer’s Detection Using Speech and Large Language Models
Proc. Interspeech, 2025.
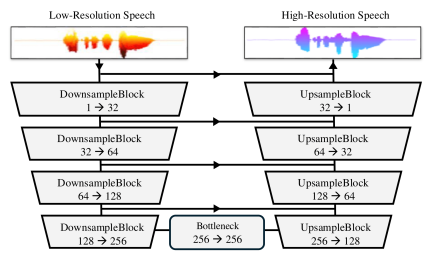
Wave-U-Mamba: An End-To-End Framework For High-Quality And Efficient Speech Super Resolution
Proc. ICASSP, 2025.
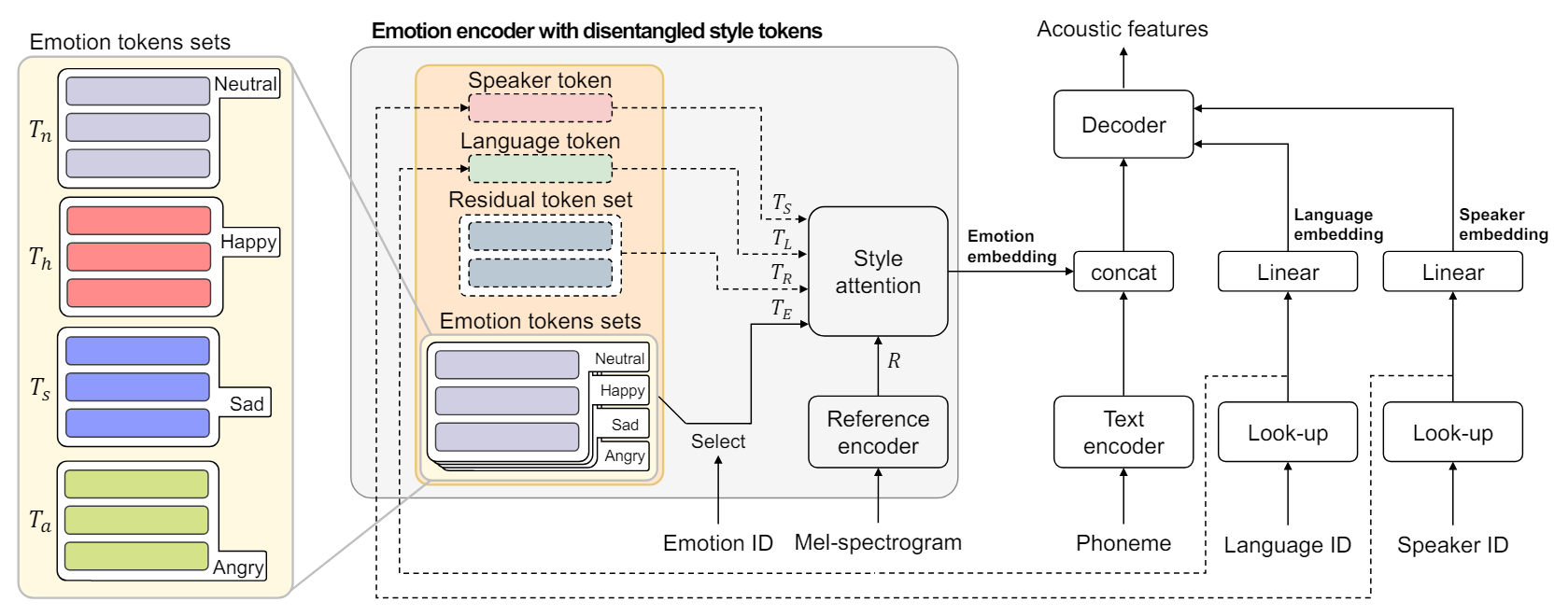
Mels-Tts: Multi-Emotion Multi-Lingual Multi-Speaker Text-To-Speech System Via Disentangled Style Tokens
Proc. ICASSP, 2024.
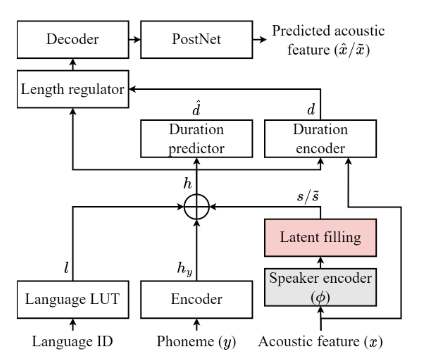
Latent Filling: Latent Space Data Augmentation for Zero-Shot Speech Synthesis
Proc. ICASSP, 2024.
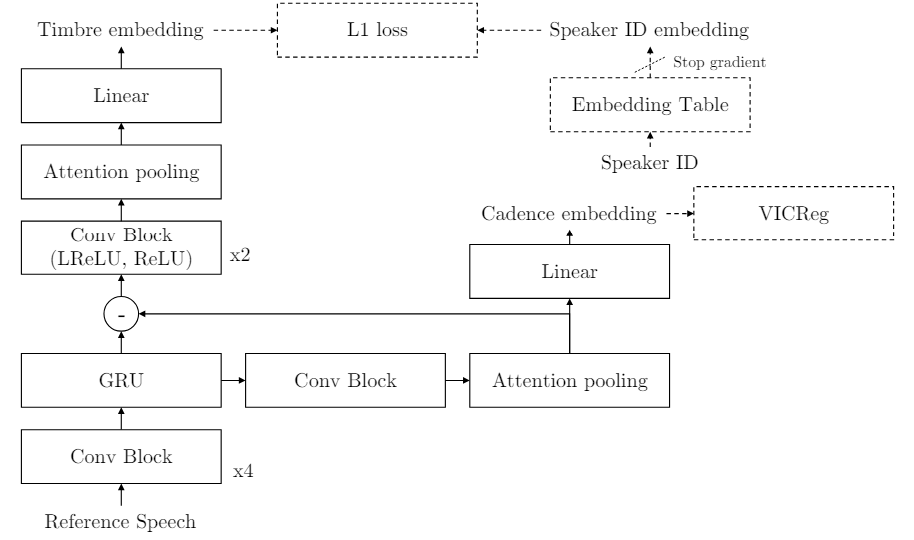
Hierarchical Timbre-Cadence Speaker Encoder for Zero-shot Speech Synthesis
Proc. INTERSPEECH, 2023.
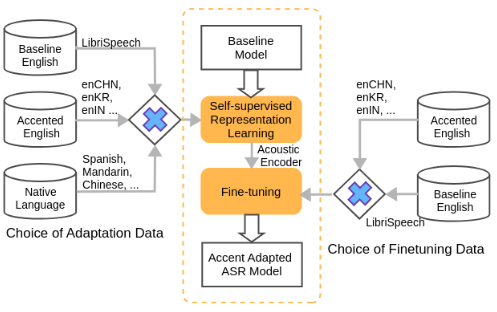
Self-Supervised Accent Learning for Under-Resourced Accents Using Native Language Data
Proc. ICASSP, 2023.
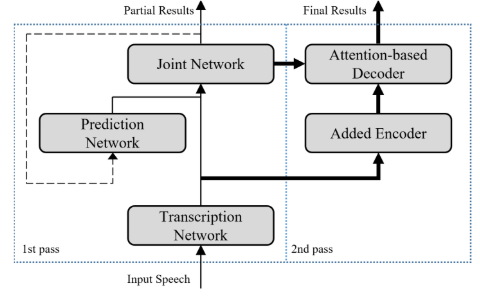
Conformer-Based on-Device Streaming Speech Recognition with KD Compression and Two-Pass Architecture
Proc. SLT, 2022.
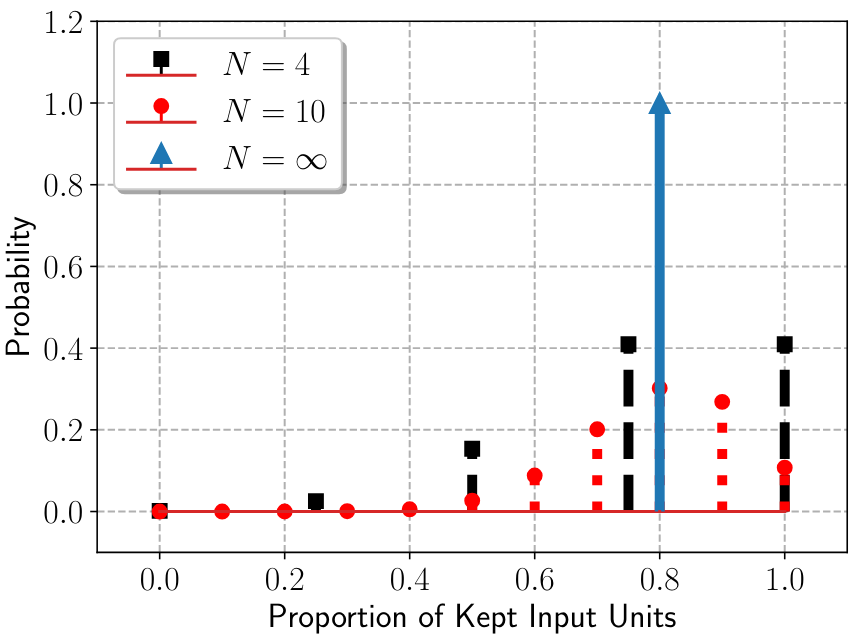
Macro-Block Dropout for Improved Regularization in Training End-to-End Speech Recognition Models
Proc. SLT, 2022.